Spark configurations are critical in controlling the behavior of your data processing tasks. These configurations influence various aspects of Spark’s performance, from memory management to execution behavior. Typically, these settings are adjusted at the session level, meaning they apply only to the specific Spark session in which they are set. This granularity allows for fine-tuning of data operations, ensuring that each task is optimized for its specific requirements.
One of the challenges in using Spark is the repetitive nature of configuring each notebook or session individually. For instance, when optimizing the writing of Delta tables — a common operation in data engineering — specific Spark configurations need to be set. These might include settings for shuffle partition sizes or the maximum size of output files. Setting these configurations for every new notebook or session can be time-consuming.
Setting Environment-Level Spark Configuration
To address this challenge, Microsoft Fabric offers a solution: setting Spark configurations at the environment level. This approach allows you to define configurations that are applied to all sessions within the environment, eliminating the need for repetitive individual session configurations. Here’s how you can do it:
- Navigate to your Fabric Workspace and go to New > Environment.
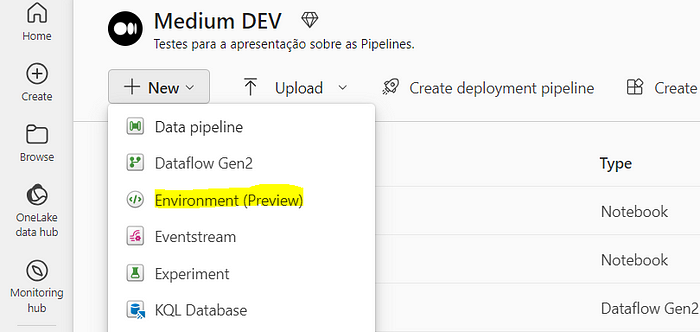
2. After you create an Environment, you have the option to set default spark properties for this environment.
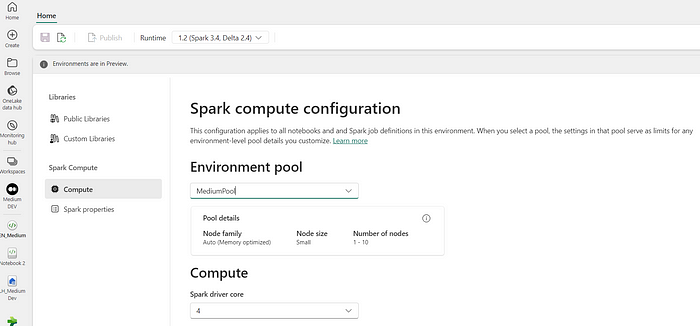
3. Select the sparking pool that will be used when you run spark on this environment, then select Spark Properties, now you can Add a new property.
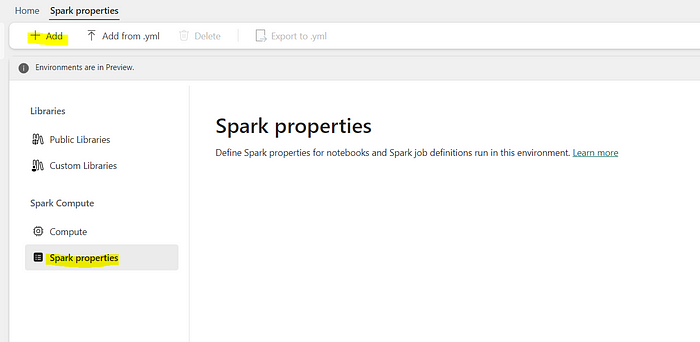
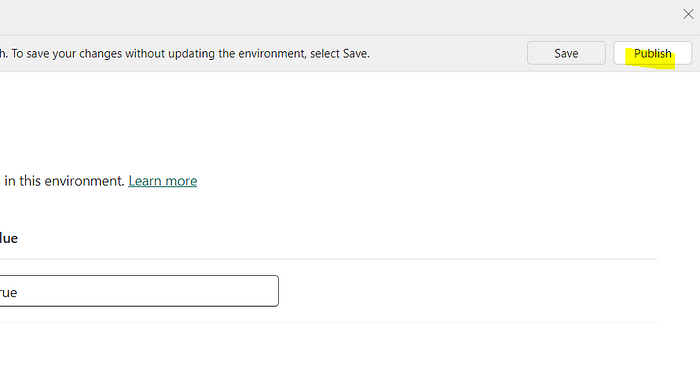
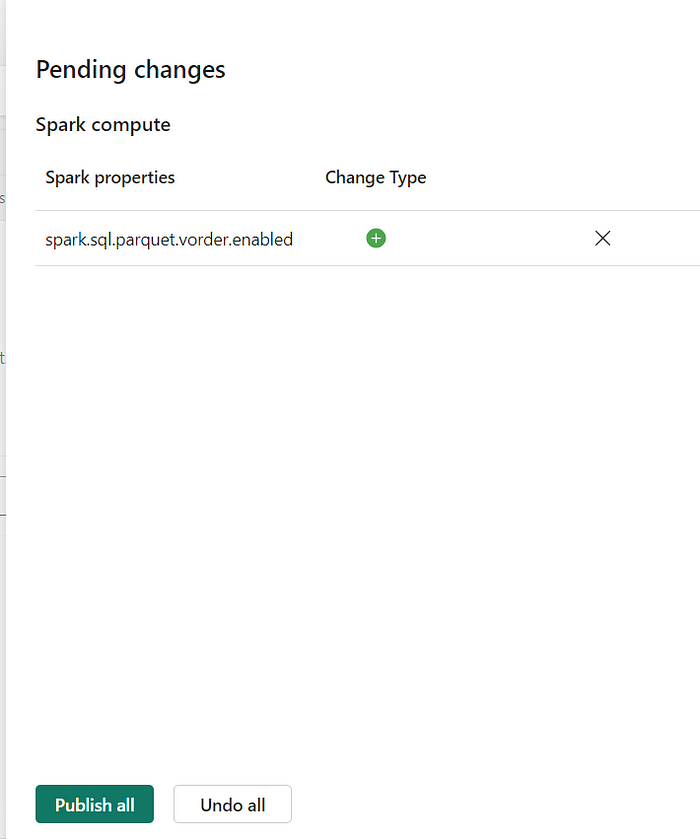
4. For example, let´s set the property spark.sql.parquet.vorder.enabled to true on this environment.
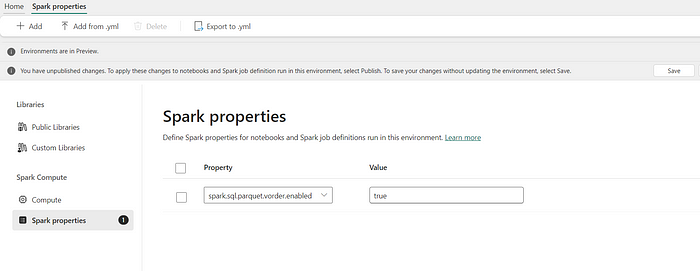
5. Hit Publish so the changes take effect.
Check Configurations

After the environment and properties are set stop and rerun your spark session using the environment you´ve just created.
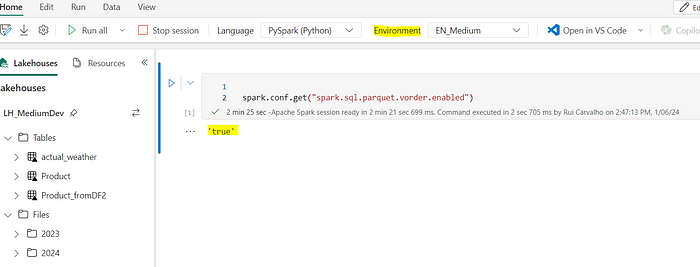
Session Management and Configuration Application
It’s important to note that these settings take effect at the start of a new Spark session. If you have an ongoing session, you’ll need to restart it for the new configurations to apply. This ensures that all notebooks or processes started after the change will automatically inherit the new settings, streamlining your workflow.
Best Practices
- Always validate your configurations for syntax and compatibility.
- Be cautious with global changes; what works for one process might not be ideal for another.
- Regularly review and update your configurations to align with your evolving data processing needs.
Conclusion
Setting Spark configurations at the environment level in Microsoft Fabric Workspace is something that simplifies the management of Spark sessions, ensures consistency across different processes, and saves valuable time. By following the steps and best practices outlined in this article, you can optimize your data operations, harnessing the full power of Spark in your data engineering endeavors.
About the Author:
Data Enthusiast | Time Management and Productivity | Book Lover | One of my passions is to teach what´ve learned | Stories every week.
Reference:







 Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
