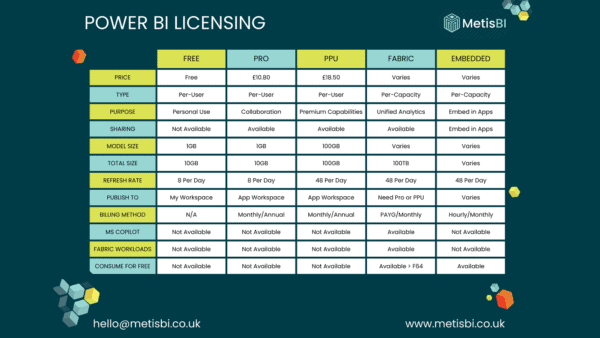
Microsoft Fabric uses a data lakehouse architecture, which means it does not use a relational data warehouse (with its relational engine and relational storage) and instead uses only a data lake to store data. Data is stored in Delta lake format so that the data lake acquires relational data warehouse-like features (check out my book that goes into much detail on this, or my video). Here is what a typical architecture looks like when using Fabric (click here for the .vsd):

This section describes the five stages of data movement within a data lakehouse architecture, as indicated by the numbered steps in the diagram above. While I highlight the most commonly used Microsoft Fabric features for each stage, other options may also be applicable:
- Ingest – A data lakehouse can handle any type of data from many sources including on-prem and in the cloud. The data may vary in size, speed, and type; it can be unstructured, semi-structured, or relational; it can come in batches or via real-time streaming; it can come in small files or massive ones. ELT processes will be written to copy this data from the source systems into the raw layer (bronze) of the data lake. In Fabric, you will use features such as Azure IoT Hubs and Eventstream for real-time streaming, and data pipelines for batch processing
- Store – Storing all the data in a data lake results in a single version of the truth and allows end-users to access it no matter where they are as long as they have a connection to the cloud. In Fabric, OneLake is used for the data lake (which uses ADLS Gen2 under the covers). Fabric shortcuts can be used to access data sources outside of OneLake (such as other data lakes on ADLS Gen2 or AWS S3), and mirroring can be used to copy data from data sources into OneLake in real-time (such as Snowflake or Azure SQL Database)
- Transform – A data lake is just storage, so in this step compute resources are used to copy files from the raw layer in the data lake into a conformed folder, which simply converts all the files to Delta format (which under the covers uses Parquet and a Delta log). Then the data is transformed (enriching and cleaning it) and stored in the cleaned layer (silver) of the data lake. Next, the computing tool takes the files from the cleaned layer and curates the data for performance or ease of use (such as joining data from multiple files and aggregating it) and then writes it to the presentation layer (gold) in the data lake. If you are implementing Master Data Management (MDM) with a tool such as Profisee, the MDM would be done between the cleaned and presentation layers. Within the presentation layer you may also want to copy the data into a star schema for performance reasons and simplification. You might need more or less layers in the data lake, depending on the size, speed, and type of your data. Also important is the folder structure of each layer – see Data lake architecture and Serving layers with a data lake. Within all the layers the data can either be stored in a Fabric lakehouse or warehouse (see Microsoft Fabric: Lakehouse vs Warehouse video). In Fabric, for the compute required to transform data, you can use features such as Dataflow Gen2, Spark notebooks, or stored procedures
- Model – Reporting directly from the data in a data lake can be confusing for end-users, especially if they are used to a relational data warehouse. Because Delta Lake is schema-on-read, the schema is applied to the data when it is read, not beforehand. Delta Lake is a file-folder system, so it doesn’t provide context for what the data is. (Contrast that with a relation data warehouse’s metadata presentation layer, which is on top of and tied directly to the data). Also, defined relationships don’t exist within Delta Lake. Each file is in its own isolated island, so you need to create a “serving layer” on top of the data in Delta Lake to tie the metadata directly to the data. To help end users understand the data, you will likely want to present it in a relational data model, so that makes what you’re building a “relational serving layer.” With this layer on top of the data, if you need to join more than one file together, you can define the relationships between them. The relational serving layer can take many forms such as a SQL view or a semantic model in star schema format in Power BI. If done correctly, the end user will have no idea they are actually pulling data from a Delta Lake—they will think it is from the relational data warehouse
- Visualize – Once the relational serving layer exposes the data in an easy-to-understand format, end-users can easily analyze the data using familiar tools to create reports and dashboards. In Fabric, you would use Power BI for building reports and dashboards
A few more things to call-out in the diagram: a data scientist can use the ML model feature in Fabric on the data in OneLake. Often a sandbox layer is created where some of the raw data is copied to, which allows the data scientist to modify the data for their own purposes without affecting everyone else. Also, Microsoft Purview can be used as a data catalog to make everyone aware of all the data and reports in the data lakehouse and to request access to those items.
In the end, data is moved along in this architecture and copied multiple times, resulting in more cost and complexity. However, all this work done by IT has the benefit of making the data really easy for end-users to query and build reports, resulting in self-service BI, so IT gets out of the business of building reports.
About The Author

Serra, J. (2024). Microsoft Fabric reference architecture. Available at: Microsoft Fabric reference architecture | James Serra’s Blog [Accessed: 15th August 2024].


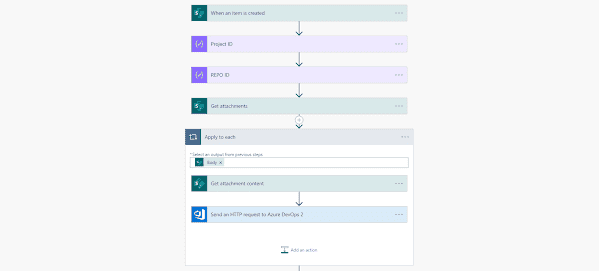



 Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
