Articles in this design series:
- 1 – Introduction
- 2 – High-Level Design
- 3 – Trusted Data Products
- 4 – Gold Data Products
- 5 – Benefits & Drawbacks
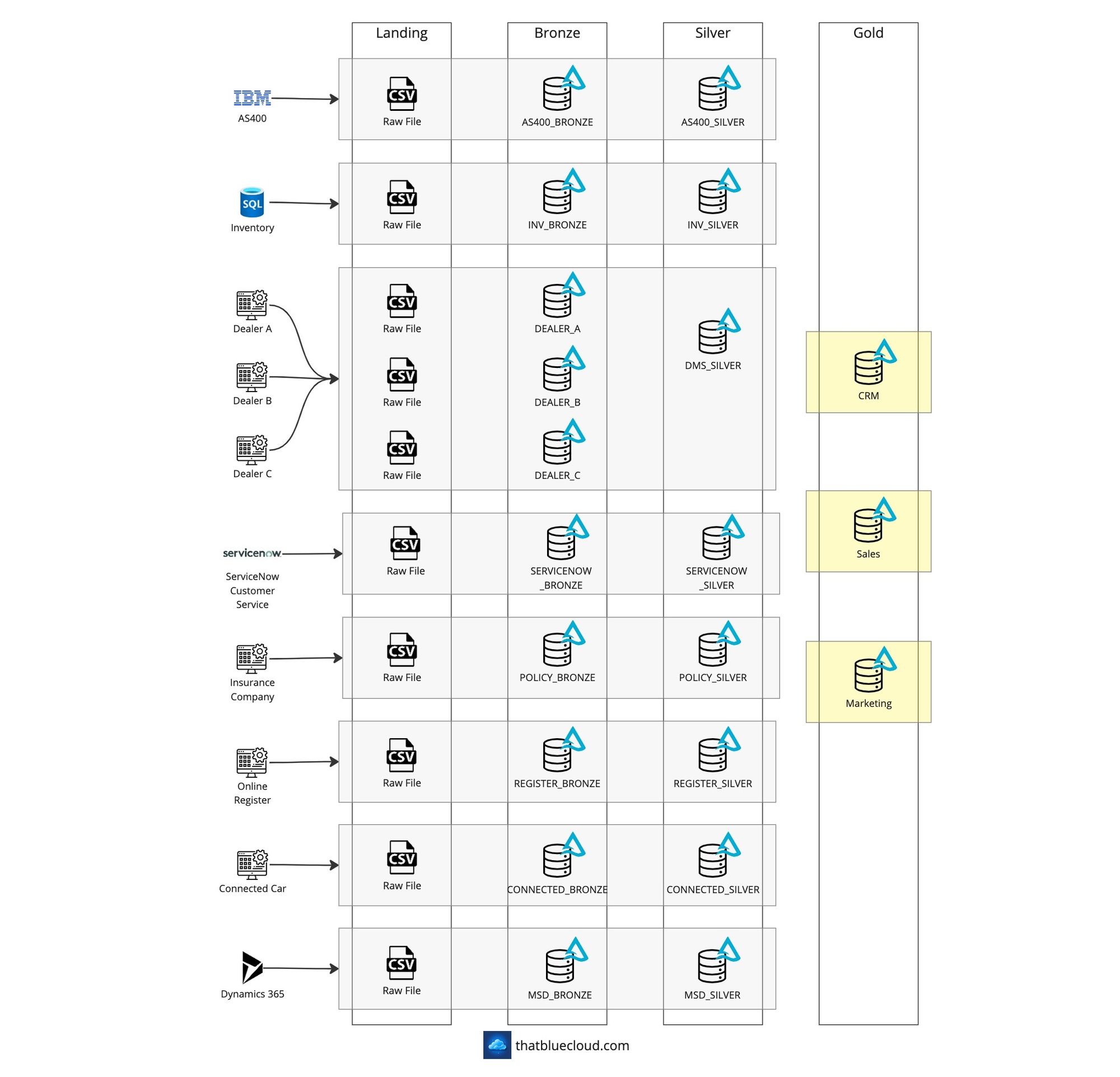
During my career of almost 15 years, I had the chance to work with two different automotive companies. In one, I helped build their Dealer Management System (DMS), which the car dealers would use for several things: Vehicle orders, spare part stocks, work orders, appointments, customer relationships, etc. On the other, I helped expand their data platform to other source systems, bring in more data, and ship out more data. In both companies, I had the chance to work with the data from start to finish.
Many automotive companies use a combination of hybrid clouds (on-premise + a cloud vendor). Some of their on-premise systems have been built over almost 30 years, and even their manufacturing platforms run on them. AS400 is widespread, with the data kept in a DB2 database.
Whilst most data pipelines operate on nightly batch runs on a schedule, they also have valid near-realtime and realtime use cases. Some of the data is even kept on their dealers’ systems, so they have to integrate with every one of them. These integrations get complicated, and the data quality is always a problem. Sometimes, getting a clear view of what’s happening is tough.
Although both companies I worked with have their data platforms built and are operational, I wanted to design a data platform that can combine all their requirements and solve them with a unified approach. It used to be very expensive and challenging to build Data Warehouses (and still is). Still, with the Lakehouses and Medallion Architecture, making a flexible data platform that can operate on batch or streaming datasets is much easier.

Before we continue, this is a solution design, not a fully-fledged implementation. We won’t be writing extensive Lakehouse/Warehouse building queries or deploying the infrastructure. This is purely an exercise to design the solution based on the automotive sector’s most common data requirements.

Just beware: This is a design that I came up with, and it doesn’t contain any IP from the companies I worked with. This is my take on the same problem they have been facing, and trying to develop an alternative and comprehensive solution.
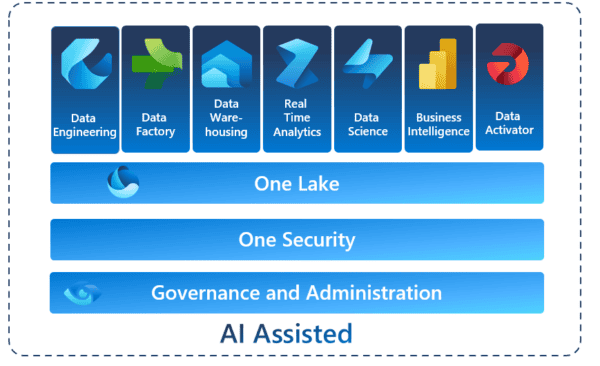
Why Fabric
Although still in preview, Fabric is an all-in-one data platform that combines the best of Synapse Analytics, Data Lake and Power Platform. It has the capability of ingesting & processing large datasets and drawing insights and analytics from them for business value. It is also a SaaS service, which makes the deployment and management of it a breeze.
I’ve written extensively on the capabilities of Fabric and compared it to Synapse Analytics. I’m dropping the links for these articles below if you would like to take a look:
- Microsoft Fabric vs. Azure Synapse Analytics
- OneLake vs ADLS Gen2: Full Feature Comparison
- Should You Migrate To Fabric?
- Adopting Fabric: Moving From Synapse Analytics To Microsoft Fabric
What I’ll Demonstrate

Here are a few capabilities we’ll cover:
- Pull data from On-Premise and Azure data sources
- Design Fabric Workspaces according to Medallion Architecture
- Discuss the reasons for design decisions, based on each source
- Creating trusted and gold products within the Fabric
- Reusing the Silver layer in multiple data products
Additionally, I’m working under the assumption that the following features will be released for Fabric in the next few weeks, so the design is making use of them:
- VNET Data Gateways for Fabric Pipelines and Dataflows
- Synapse Link for Fabric
Basic Requirements
First and foremost, automotive companies have complex manufacturing systems and operate on a different level of realtime requirements. I’m not trying to tackle any of those. I’m trying to combine the outputs of their multiple systems and create a Lakehouse that can support teams like Marketing, Sales, Operations, Fleet, etc. I’m not trying to tackle the problems of the manufacturing line. That’s way beyond my expertise, and I didn’t get to work with those before.
The requirements are virtually endless, but for the simplicity of our example, I’ll limit them to the following:
- From when a dealer orders the vehicle, received and sold by them, the vehicle’s lifecycle needs to be monitored. The car’s status, from the order to the delivery, must be tracked.
- The customer information is distributed across multiple systems (order, policy, customer service, etc.) and needs to be collated for marketing campaigns to operate on. The customer records will be combined and segmented. Customers’ consent is required to be registered and kept track of.
- The dealers’ sales performance needs tracking. Commitments, orders, sales and performance need to be compared and monitored.
- Companies are also involved in used car sales through their dealers. These used car sales also need to be tracked and compared against KPIs.
- During the sales experience, a customer can purchase insurance or other add-ons when purchasing the car. The insurance information and the cross-sales performance need to be monitored.
- If there’s a recall campaign for specific car models, those campaign performances need reporting.
I can grow this list indefinitely for each use case, but I’m choosing to focus on the basic requirements of Sales and Marketing related parts to keep the universe limited.
- It’ll only keep the last two years of data in the Lakehouse, based on the record created date. This is to optimise the performance, but keep it in mind.
- Very, very preview feature. It may change dramatically in the future.
About the Author:
I’m a cloud solutions architect with a coffee obsession. Have been building apps and data platforms for over 18 years, I also blog on Azure & Microsoft Fabric. Feel free to say hi on Twitter/X!
Reference:






 Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
Using a SharePoint Online list as a Knowledge source via ACTIONS in Copilot AI Studio
