Some third party applications usually ask for JSON files as input to import new data. An example is Splunk, a software platform to search, analyze and visualize the machine-generated data gathered from the websites, applications, sensors, devices etc. If the JSON format is mandatory for sharing information and the data you need to analyze is stored in a database, you need to transform your data from a tabular format to a JSON one, following a JSON schema. If you give this task to developers, the first idea they usually follow is to develop an application (in C#, Java or whatever programming language) that connects to the source database, loads data using an ORM (with consequent possible performance issues due to the inability to write optimum SQL code), transforms them using proper libraries and then exports the output in a JSON file. But if your data is stored in a Microsoft SQL Server Database, you are lucky, since starting from the 2016 version for the on-premises version and on Azure SQL Database, you can manage JSON data directly into your RDBMS.
Sample Database
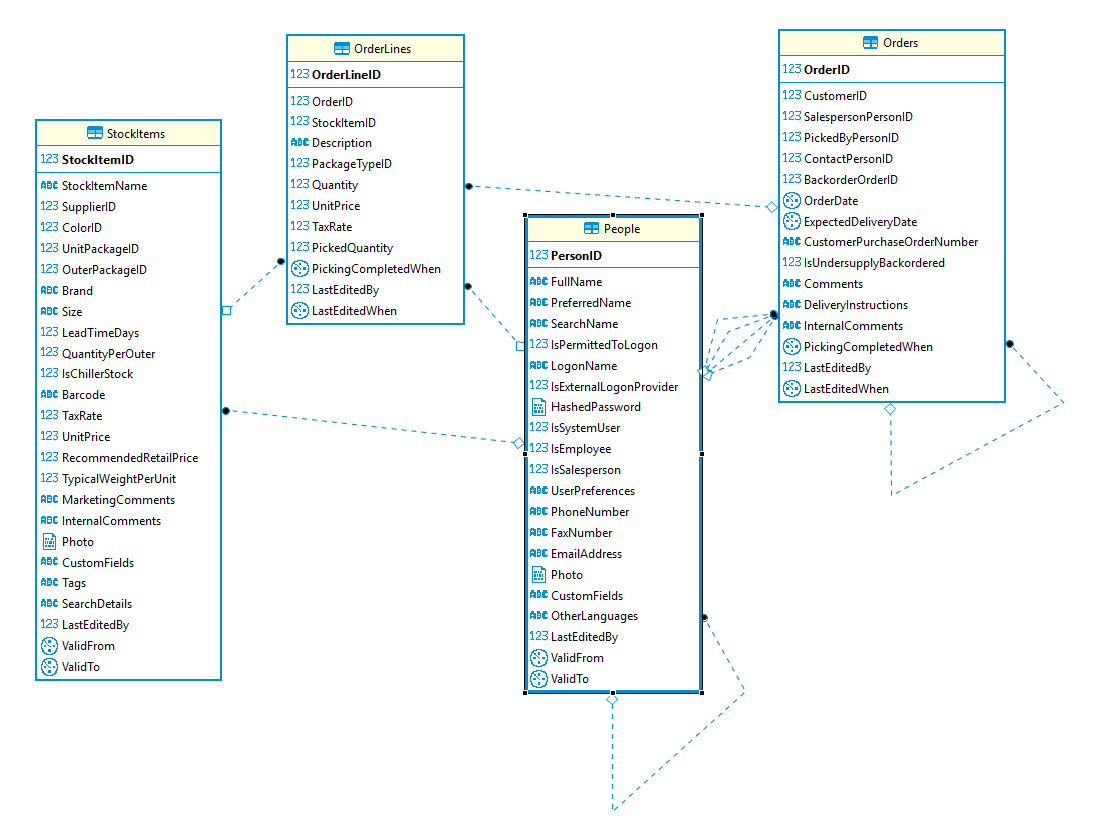
The database we’ll use for our examples is the WideWorldImporters Sample one. For an overview of its content, check the corresponding documentation.
The following is an ER diagram of the tables we’ll use in our queries:
SQL Server JSON Capabilities
Starting from SQL Server 2016 on-premises and in Azure SQL Database, you can use built-in functions and operators to do the following things with JSON text:
- Parse JSON text and read or modify values
- Transform arrays of JSON objects into table format
- Run any T-SQL query on the converted JSON objects
- Format the results of T-SQL queries in JSON format
This article is focused on the third point, i.e. how to properly manage your result set given by a complex query, in order to get your nested JSON in the right format as output.
Basically, you have two methods to generate JSON results using the FOR JSON clause: FOR JSON AUTO and FOR JSON PATH.
FOR JSON AUTO Limitations
As you can read into the official docs, “when you specify the AUTO option, the format of the JSON output is automatically determined based on the order of columns in the SELECT list and their source tables. You can’t change this format”.
Order of SELECT Columns
Let’s try this. Suppose you want to share few details about a couple of orders with an external application. First of all, we need to gather data in a tabular format:
SELECT
code = orders.CustomerPurchaseOrderNumber,
[date] = orders.OrderDate,
line = details.OrderLineID,
amount = details.Quantity * details.UnitPrice
FROM Sales.Orders AS orders
INNER JOIN Sales.OrderLines AS details
ON orders.OrderID = details.OrderID
WHERE orders.OrderId IN (1, 2)
Here the result:
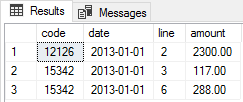
As you can see, the order with code 15342 has two lines. Now, let’s transform this result set in a JSON text adding “FOR JSON AUTO” at the end of the previous query first and then swapping the SELECT columns, running the following two queries:
SELECT
code = orders.CustomerPurchaseOrderNumber,
[date] = orders.OrderDate,
line = details.OrderLineID,
amount = details.Quantity * details.UnitPrice
FROM Sales.Orders AS orders
INNER JOIN Sales.OrderLines AS details
ON orders.OrderID = details.OrderID
WHERE orders.OrderId IN (1, 2)
FOR JSON AUTO;
SELECT
line = details.OrderLineID,
amount = details.Quantity * details.UnitPrice,
code = orders.CustomerPurchaseOrderNumber,
[date] = orders.OrderDate
FROM Sales.Orders AS orders
INNER JOIN Sales.OrderLines AS details
ON orders.OrderID = details.OrderID
WHERE orders.OrderId IN (1, 2)
FOR JSON AUTO;
You’ll get the following different results:
[{
"code": "12126",
"date": "2013-01-01",
"details": [{
"line": 2,
"amount": 2300.00
}
]
}, {
"code": "15342",
"date": "2013-01-01",
"details": [{
"line": 3,
"amount": 117.00
}, {
"line": 6,
"amount": 288.00
}
]
}
]
[{
"line": 2,
"amount": 2300.00,
"orders": [{
"code": "12126",
"date": "2013-01-01"
}
]
}, {
"line": 3,
"amount": 117.00,
"orders": [{
"code": "15342",
"date": "2013-01-01"
}
]
}, {
"line": 6,
"amount": 288.00,
"orders": [{
"code": "15342",
"date": "2013-01-01"
}
]
}
]
Actually the JSON result isn’t formatted as you can see in the previous code if you use SQL Server Management Studio as client. You’ll get one single line of JSON text. You can click on it and save the file with the .json extension. Then I use the JSTool extension for Notepad++, but you can use whatever formatting tool you want (Visual Studio Code, online services like JSON Formatter, etc.). You can also open the JSON file in a browser to get a good visualization of it. For example, in Firefox you’ll have the following UI:

If instead you’re using Azure Data Studio, after clicking on the JSON result, it will be automatically formatted in a new tab if it is not too much large, otherwise a single line will be shown and the formatting option will be disabled.
Getting back to our example, the nesting order of orders and details swaps according to the order of the columns (and indirectly of the source tables in join) you used in your SELECT statement in this way:
- Each table corresponds to a nesting section. The first section to be nested (level 0) is the one corresponding to the first column used in the SELECT statement. Then all the other columns of that table/section present in the SELECT statement will be grouped together, even if their place is not consecutive to the first column.
- The first column used in the SELECT statement that is not contained into the first table/section, determines the second nested section (level 1).
- And so on.
Multiple Nested Sections at Different Levels
Moreover, FOR JSON AUTO doesn’t allow to nest multiple sections in your JSON at different levels of your choice. For example, suppose you want to get order details like these ones, with salesPerson and details sections nested at the same level (the first one):
{
"code": "XXXX",
"date": "YYYY",
"salesPerson": [{
"fullName": "ZZZZ"
}
],
"details": [{
"line": 0000,
"amount": 1111
}
]
}
If you try a query like the following one:
SELECT
code = H.CustomerPurchaseOrderNumber,
[date] = H.OrderDate,
fullName = salesPerson.FullName,
line = details.OrderLineID,
amount = details.Quantity * details.UnitPrice
FROM Sales.Orders AS H
INNER JOIN [Application].People AS salesPerson
ON H.SalespersonPersonID = salesPerson.PersonID
INNER JOIN Sales.OrderLines AS details
ON H.OrderID = details.OrderID
WHERE H.OrderId IN (1, 2)
FOR JSON AUTO
you’ll get the following wrong result, where the details section (level 2) is nested inside the salesPerson one (level 1):
[{
"code": "12126",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Kayla Woodcock",
"details": [{
"line": 2,
"amount": 2300.00
}
]
}
]
}, {
"code": "15342",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Anthony Grosse",
"details": [{
"line": 3,
"amount": 117.00
}, {
"line": 6,
"amount": 288.00
}
]
}
]
}
]
It’s impossible to tell the SQL engine to bring the details section one level behind when using AUTO.
FOR JSON PATH Flexibility
The docs guides suggest that “to maintain full control over the output of the FOR JSON clause, specify the PATH option”. This is the only way to get arrays of JSON objects nested as you want. You can format nested results by using dot-separated column names or by using nested queries. Let’s have some examples.
CASE 1: Simple Order Details
Let’s try using only dot-separated column names to get just order headers and order details:
SELECT
code = orders.CustomerPurchaseOrderNumber,
[date] = orders.OrderDate,
[details.line] = details.OrderLineID,
[details.amount] = details.Quantity * details.UnitPrice
FROM Sales.Orders AS orders
INNER JOIN Sales.OrderLines AS details
ON orders.OrderID = details.OrderID
WHERE orders.OrderId IN (1, 2)
FOR JSON PATH
Here the result:
[{
"code": "12126",
"date": "2013-01-01",
"details": {
"line": 2,
"amount": 2300.00
}
}, {
"code": "15342",
"date": "2013-01-01",
"details": {
"line": 3,
"amount": 117.00
}
}, {
"code": "15342",
"date": "2013-01-01",
"details": {
"line": 6,
"amount": 288.00
}
}
]
As you can see, the details section is nested inside the main one, but the result consists in three order objects, one for each order line, and that is not what we want. Looking at the desired JSON result of fig. 3, details section has to be an array of lines. So the number of order objects has to be just two, one of which containing a nested details section having two lines. You can get this result using nested queries:
SELECT
code = H.CustomerPurchaseOrderNumber,
[date] = H.OrderDate,
details = ( SELECT
line = D.OrderLineID,
amount = D.Quantity * D.UnitPrice
FROM Sales.OrderLines AS D
WHERE H.OrderID = D.OrderID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Sales.Orders AS H
WHERE H.OrderId IN (1, 2)
FOR JSON PATH, INCLUDE_NULL_VALUES
Now the result is the desired one:
[{
"code": "12126",
"date": "2013-01-01",
"details": [{
"line": 2,
"amount": 2300.00
}
]
}, {
"code": "15342",
"date": "2013-01-01",
"details": [{
"line": 3,
"amount": 117.00
}, {
"line": 6,
"amount": 288.00
}
]
}
]
CASE 2: Order and Sales Person Details
Now let’s add the Sales Person details to the previous query. The Sales Person section has to be at the same nesting level of the Details one. Both sections have to be arrays, so nested queries are the way to format your JSON in the right way:
SELECT
code = H.CustomerPurchaseOrderNumber,
[date] = H.OrderDate,
salesPerson = ( SELECT
fullName = P.FullName,
customFields = P.CustomFields
FROM [Application].People AS P
WHERE H.SalespersonPersonID = P.PersonID
FOR JSON PATH, INCLUDE_NULL_VALUES),
details = ( SELECT
line = D.OrderLineID,
amount = D.Quantity * D.UnitPrice
FROM Sales.OrderLines AS D
WHERE H.OrderID = D.OrderID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Sales.Orders AS H
WHERE H.OrderId IN (1, 2)
FOR JSON PATH, INCLUDE_NULL_VALUES
Here the result:
[{
"code": "12126",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Kayla Woodcock",
"customFields": "{ \"OtherLanguages\": [\"Polish\",\"Chinese\",\"Japanese\"] ,\"HireDate\":\"2008-04-19T00:00:00\",\"Title\":\"Team Member\",\"PrimarySalesTerritory\":\"Plains\",\"CommissionRate\":\"0.98\"}"
}
],
"details": [{
"line": 2,
"amount": 2300.00
}
]
}, {
"code": "15342",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Anthony Grosse",
"customFields": "{ \"OtherLanguages\": [\"Croatian\",\"Dutch\",\"Bokmål\"] ,\"HireDate\":\"2010-07-23T00:00:00\",\"Title\":\"Team Member\",\"PrimarySalesTerritory\":\"Mideast\",\"CommissionRate\":\"0.11\"}"
}
],
"details": [{
"line": 3,
"amount": 117.00
}, {
"line": 6,
"amount": 288.00
}
]
}
]
The result looks quite good, except for the customFields value. It’s in turn a JSON text, but it isn’t interpreted as JSON. We need something to “parse” that text and transform it in full-fledged JSON.
CASE 3: Order and Sales Person Details Validating and Appending JSON text values
There are a bunch of SQL Server built-in functions to validate, query and change JSON data, as shown in doc guides. But there is nothing specific about how to validate and append a JSON text contained in a column. After playing a little bit with all the aforementioned functions I’ve obtained the desired result.
Just think of “validate and append” a JSON text like “query and extract the whole object” from it. You can do that using just the context item dollar sign ($) into the JSON path of the JSON_QUERY() function.

SELECT
code = H.CustomerPurchaseOrderNumber,
[date] = H.OrderDate,
salesPerson = ( SELECT
fullName = P.FullName,
customFields = JSON_QUERY(P.CustomFields, '$')
FROM [Application].People AS P
WHERE H.SalespersonPersonID = P.PersonID
FOR JSON PATH, INCLUDE_NULL_VALUES),
details = ( SELECT
line = D.OrderLineID,
amount = D.Quantity * D.UnitPrice
FROM Sales.OrderLines AS D
WHERE H.OrderID = D.OrderID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Sales.Orders AS H
WHERE H.OrderId IN (1, 2)
FOR JSON PATH, INCLUDE_NULL_VALUES
Now the result is the one expected:
[{
"code": "12126",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Kayla Woodcock",
"customFields": {
"OtherLanguages": ["Polish", "Chinese", "Japanese"],
"HireDate": "2008-04-19T00:00:00",
"Title": "Team Member",
"PrimarySalesTerritory": "Plains",
"CommissionRate": "0.98"
}
}
],
"details": [{
"line": 2,
"amount": 2300.00
}
]
}, {
"code": "15342",
"date": "2013-01-01",
"salesPerson": [{
"fullName": "Anthony Grosse",
"customFields": {
"OtherLanguages": ["Croatian", "Dutch", "Bokmål"],
"HireDate": "2010-07-23T00:00:00",
"Title": "Team Member",
"PrimarySalesTerritory": "Mideast",
"CommissionRate": "0.11"
}
}
],
"details": [{
"line": 3,
"amount": 117.00
}, {
"line": 6,
"amount": 288.00
}
]
}
]
Performances of Nested Queries
Nested queries we used previously are also called correlated sub-queries and they often lead to poor performances when tables with a non trivial number of rows are involved. This is due to nested loop operators this sub-queries introduce in the query plan:
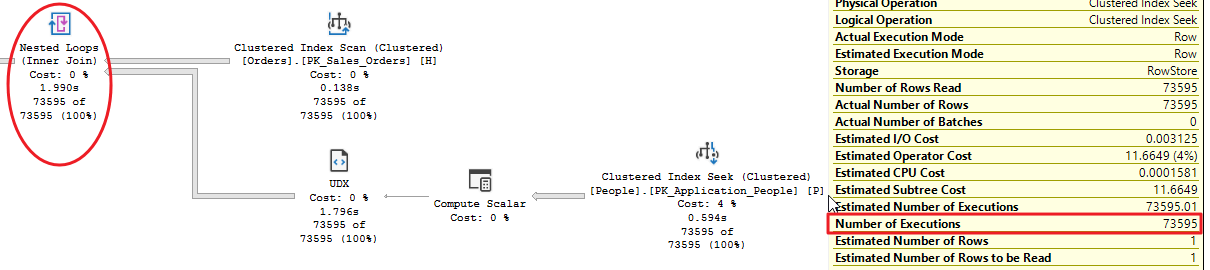
The nested loop join uses the top input as the outer input table and the bottom one as the inner input table. The outer loop consumes the outer input table row by row. The inner loop, executed for each outer row, searches for matching rows in the inner input table.
Sometimes you have to deal with deep nested JSON files derived from the joining of huge tables. In that case, using correlated sub-queries in a shot to get all the nested sections will lead to a query having worst performances.
Get All Your Columns First And Then Use Nested Queries
A good strategy to improve the query performance is the following:
1) Get all the columns you need avoiding nested queries and just using simple joins, taking care to keep also in the SELECT statement all the JOIN columns used in each JOIN clause. You’ll get the benefit of any existing indexes to get this result set faster. Then persist it in a temp table.
2) Use the temp table multiple times, one for each nested section, using nested queries to format your JSON result.
An example is worth a thousand words. Consider the following query:
SELECT
code = H.CustomerPurchaseOrderNumber,
[date] = H.OrderDate,
salesPerson = ( SELECT
fullName = P.FullName,
customFields = JSON_QUERY(P.CustomFields, '$')
FROM [Application].People AS P
WHERE H.SalespersonPersonID = P.PersonID
FOR JSON PATH, INCLUDE_NULL_VALUES),
details = ( SELECT
line = D.OrderLineID,
amount = D.Quantity * D.UnitPrice,
stockItem = ( SELECT
[name] = SI.StockItemName,
unitPrice = SI.UnitPrice,
supplier = ( SELECT
fullName = SUP.FullName,
customFields = JSON_QUERY(SUP.CustomFields, '$')
FROM [Application].People AS SUP
WHERE SUP.PersonID = SI.SupplierID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Warehouse.StockItems AS SI
WHERE SI.StockItemID = D.StockItemID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Sales.OrderLines AS D
WHERE H.OrderID = D.OrderID
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM Sales.Orders AS H
FOR JSON PATH, INCLUDE_NULL_VALUES;
This is not the case, but if tables had been bigger than the ones used as source, the previous query would have taken a long time to complete. In that case, get all your needed columns in tabular form using simple joins (including also all the join columns of the involved tables), and then persist the result set in a temporary table:
SELECT … salesPerson = ( SELECT fullName = SalesPerson.salesPerson_fullName, customFields = JSON_QUERY(SalesPerson.salesPerson_customFields, ‘$’) FROM #Orders AS SalesPerson WHERE Orders.salespersonPersonId = SalesPerson.salesPerson_id GROUP BY SalesPerson.salesPerson_fullName, SalesPerson.salesPerson_customFields FOR JSON PATH, INCLUDE_NULL_VALUES), … FROM …Given the #Orders table, you can rewrite, for example, the nested section salesPerson in this way:
IF OBJECT_ID('tempdb..#OrderDetails') IS NOT NULL
DROP TABLE #OrderDetails;
SELECT
orderId = Details.details_orderId,
line = Details.details_line,
amount = Details.details_amount,
stockItemJson = ( SELECT
[name] = StockItem.details_stockItem_name,
unitPrice = StockItem.details_stockItem_unitPrice,
supplier = ( SELECT
fullName = SUP.FullName,
customFields = JSON_QUERY(SUP.CustomFields, '$')
FROM [Application].People AS SUP
WHERE SUP.PersonID = StockItem.details_stockItem_supplierId
GROUP BY
SUP.FullName,
SUP.CustomFields
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM #Orders AS StockItem
WHERE StockItem.details_stockItem_id = Details.details_stockItemId
GROUP BY
StockItem.details_stockItem_name,
StockItem.details_stockItem_unitPrice,
StockItem.details_stockItem_id,
StockItem.details_stockItem_supplierId
FOR JSON PATH, INCLUDE_NULL_VALUES )
INTO #OrderDetails
FROM #Orders AS Details
GROUP BY
Details.details_orderId,
Details.details_line,
Details.details_amount,
Details.details_stockItemId;
You have to use the GROUP BY since the #Orders table has a finer granularity then the salesPerson entity. You could be tempted to use the DISTINCT statement to eliminate duplicates, but in our case it’ll be a disaster from a performance point of view.
DISTINCT collects all of the rows and then tosses out duplicates. GROUP BY can filter out the duplicate rows before performing any of that work.
Each nested section has a WHERE clause used to be related to its external section. A GROUP BY will resolve the WHERE clause before getting rid of the duplicates, improving the performances of the query. For more information, read this blog post by Aaron Bertrand.
Since the details section contains two nested sections (details → stockitem → supplier), it’s recommended to persist all the details in another temp table to gain better performances in this way:
Notice that all the stockItem section is “compressed” in one column (stockItemJson) using JSON text. So you can easily expand it using JSON_QUERY as explained before.
At this point you can get the same result as the query in fig. 5 with the following one:
SELECT
Orders.code,
Orders.[date],
salesPerson = ( SELECT
fullName = SalesPerson.salesPerson_fullName,
customFields = JSON_QUERY(SalesPerson.salesPerson_customFields, '$')
FROM #Orders AS SalesPerson
WHERE Orders.salespersonPersonId = SalesPerson.salesPerson_id
GROUP BY
SalesPerson.salesPerson_fullName,
SalesPerson.salesPerson_customFields
FOR JSON PATH, INCLUDE_NULL_VALUES),
details = ( SELECT
line,
amount,
stockItem = JSON_QUERY(Details.stockItemJson, '$')
FROM #OrderDetails AS Details
WHERE Orders.orderID = Details.orderId
FOR JSON PATH, INCLUDE_NULL_VALUES )
FROM #Orders AS Orders
GROUP BY
Orders.code,
Orders.[date],
Orders.salespersonPersonId,
Orders.orderID
FOR JSON PATH, INCLUDE_NULL_VALUES;
Performance Gains On a Production Environment
I’ve recently adopted this strategy for a customer who needed to extract JSON files from his data. One of the JSON files had these requirements:
- The base result set in tabular form is generated by the joining of 26 tables
- The top 3 biggest tables have 543mln, 105mln, 90mln of rows respectively
- The file has to be generated every 5 minutes, getting only the last arrived entities (from 3K to 5K entities)
- The deepest nested level of the resulting JSON is the 6th one
The execution of the “original” query, made up by correlated sub-queries directly based on source tables, was still running after 10 minutes.
After applying the upon mentioned strategy, I got the JSON file (using an Integration Services dtsx package; I could have used the BCP utility, but it had a bug with JSON results when I wrote this post) in just 1 minute and 30 seconds!
Conclusions
If your main data is persisted in an (Azure) SQL Server database (a version ≥ 2016 is needed for the on-premises database) and you need to extract your data in a JSON format, you don’t need to develop an external application to do that. (Azure) SQL Server already has built-in functions to manipulate JSON data.
Since the flexible formatting of a JSON text requires the using of correlated sub-queries to get it, it’s quite easy to write a query that will have bad performance when executed. So a strategy of proper refactoring of this “original” query has been explained in this blog post.
About the Author:
Mentor & Technical Director @ SolidQ. Classical pianist in the free time
Reference:
Zavarella, L.(2020).Available at: https://medium.com/microsoftazure/get-correctly-formatted-deep-nested-json-files-at-scale-directly-from-azure-sql-server-c1e112dc3c37 [Accessed: 20th May 2020].
Check out more great Azure content here